什么是Prometheus?
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
2016年由Google发起Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation), 将Prometheus纳入其下第二大开源项目。
Prometheus目前在开源社区相当活跃。
Prometheus和Heapster(Heapster是K8S的一个子项目,用于获取集群的性能数据。)相比功能更完善、更全面。Prometheus性能也足够支撑上万台规模的集群。
Prometheus的特点
- 多维度数据模型。
- 灵活的查询语言。
- 不依赖分布式存储,单个服务器节点是自主的。
- 通过基于HTTP的pull方式采集时序数据。
- 可以通过中间网关进行时序列数据推送。
- 通过服务发现或者静态配置来发现目标服务对象。
- 支持多种多样的图表和界面展示,比如Grafana等。
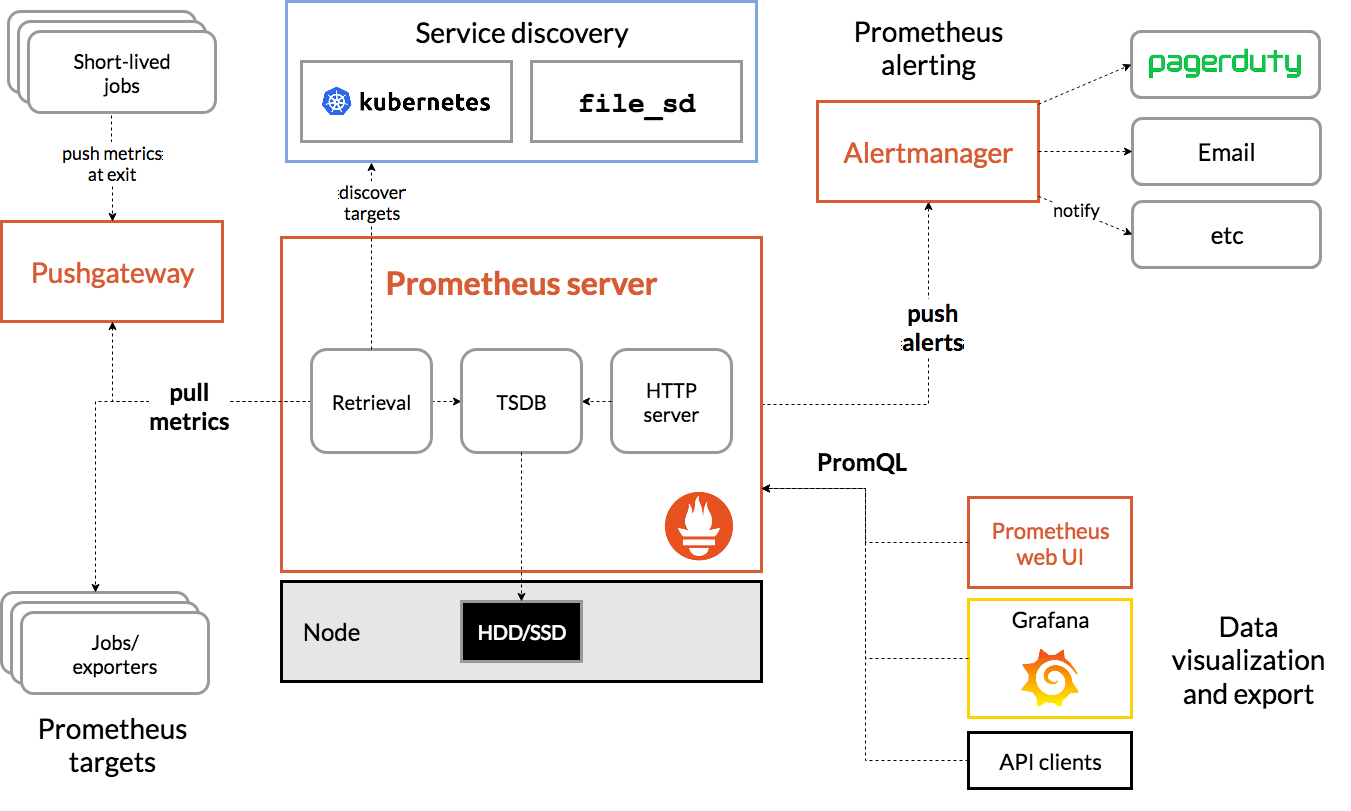
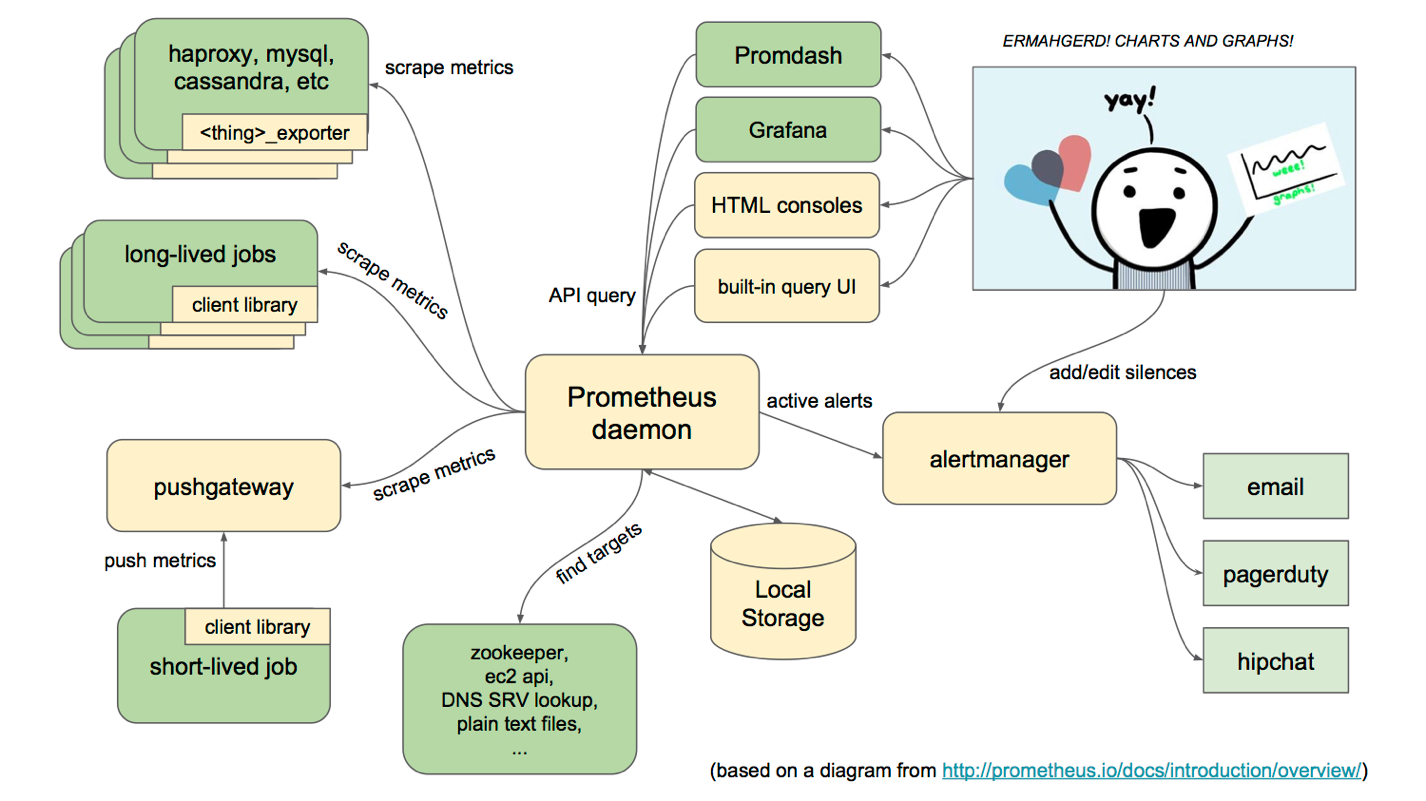
架构图
 uploadpic/prometheus
uploadpic/prometheus

基本原理
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
服务过程
- Prometheus Daemon负责定时去目标上抓取metrics(指标)数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。Prometheus采用PULL的方式进行监控,即服务器可以直接通过目标PULL数据或者间接地通过中间网关来Push数据。
- Prometheus在本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。
- Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
- PushGateway支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
- Alertmanager是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
三大套件
- Server 主要负责数据采集和存储,提供PromQL查询语言的支持。
- Alertmanager 警告管理器,用来进行报警。
- Push Gateway 支持临时性Job主动推送指标的中间网关。
Prometheus的核心数据流
Prometheus的几个关键组件:Prometheus (TSDB + Server),AlertManager,Exporters,以及周边组件Grafana。那么,这些数据是怎么来的呢?又是如何被处理和存储的呢?如果触发告警,告警是如何发送呢?
简化的数据流大概是这样的:
- Prometheus Server启动后读取配置,解析服务发现规则(xxx_sd_configs)自动收集需要监控的端点,而上述例子中的静态监控端点(static_configs)是最基础的写死的形式,而在Kubernetes中大多使用 kubernetes_sd_config。
- Prometheus Server 周期"刮取"(scrape_interval)监控端点的HTTP接口数据。
- Prometheus Server HTTP请求到达Node Exporter,Exporters返回一个文本响应,每个非注释行包含一条完整的时序数据:监控名称 + 一组标签键值对 + 样本数据。例如:node_cpu_seconds_total{cpu="0",mode="idle"} 3320.88。
- Prometheus Server收到响应,Relabel处理之后(relabel_configs),存储到TSDB文件中,根据Label建立倒排索引(Inverted Index)。
- Prometheus Server 另一个周期计算任务(周期是 evaluation_interval)开始执行,根据配置的Rules的表达式逐个计算,若结果超过阈值并持续时长超过临界点,发送Alert到AlertManager,下面会说Rule具体是什么样子的。
- AlertManager 收到原始告警请求,根据配置的策略决定是否需要触发告警,如需告警则根据配置的路由链路依次发送告警,比如邮件,企业微信,Slack,PagerDuty,通用的WebHook等等。
- 当通过界面或来自其他系统(比如Grafana)的HTTP调用查询时序数据时,传入一个PromQL表达式,Prometheus Server处理过滤完之后,返回三种类型的数据:瞬时向量 ,区间向量 ,或标量数据 (还有一个字符串类型,但目前没有用)。
对于这些数据类型的概念,具体解释如下:
- 样本数据(Sample):是一个浮点数和一个时间戳构成的时序数据基本单位;
- 瞬时向量(Instant Vector):某一时刻, 0-N条只有一个Sample的时序数据,直接查询某个指标的当前值,或用offset查询之前某个时间点的指标值,就是瞬时向量,比如:查询3分钟之前那个时间点,每个硬盘挂载点的可用空间, node_filesystem_avail_bytes offset 3m,3个挂载点则返回3条数据;
- 区间向量(Range Vector):一段时间范围内,0-N条包含M个不同时刻Sample的时序数据,比如:查询最近3分钟内,每隔30s取样的所有硬盘可用空间,node_filesystem_avail_bytes[3m],3个盘则返回3×6=18条数据;
- 标量数据(Scalar): 一个浮点数,可能是计算出来的单一结果,或是一个单纯的常量,不带任何指标或标签信息。
promethus的优缺点及特点
1、优点
2、已经有非常多的系统集成 例如:docker HAProxy Nginx JMX等等
3、服务自动化发现
4、直接集成到代码
5、设计思想是按照分布式、微服务架构来实现的
2、特点
2、PromQL,一种灵活的查询语言 ,可利用此维度
3、不依赖分布式存储;单服务器节点是自治的
4、时间序列收集通过HTTP上的拉模型进行
5、通过中间网关支持推送时间序列
6、通过服务发现或静态配置发现目标 7、多种图形和仪表板支持模式
3、不足
2、Prometheus 默认是 Pull 模型,合理规划你的网络,尽量不要转发。
3、对于集群化和水平扩展,官方和社区都没有银弹,需要合理选择 Federate、Cortex、Thanos 等方案。
4、监控系统一般情况下可用性大于一致性,容忍部分副本数据丢失,保证查询请求成功。这个后面说 Thanos 去重的时候会提到。
5、Prometheus 不一定保证数据准确,这里的不准确一是指 rate、histogram_quantile 等函数会做统计和推断,产生一些反直觉的结果,这个后面会详细展开。
二来查询范围过长要做降采样,势必会造成数据精度丢失,不过这是时序数据的特点,也是不同于日志系统的地方。
6. 通过HTTP拉取监控数据效率不够高;没有任何监控告警之外的功能(用户/角色/权限控制等等)
教程内容简介
- 1.演示安装Prometheus Server
- 2.演示通过golang和node-exporter提供metrics接口
- 3.演示pushgateway的使用
- 4.演示grafana的使用
- 5.演示alertmanager的使用
安装准备
这里我的服务器IP是10.211.55.25,登入,建立相应文件夹
mkdir -p /home/chenqionghe/promethues
mkdir -p /home/chenqionghe/promethues/server
mkdir -p /home/chenqionghe/promethues/client
touch /home/chenqionghe/promethues/server/rules.yml
chmod 777 /home/chenqionghe/promethues/server/rules.yml
下面开始三大套件的学习
一.安装Prometheus Server
通过docker方式
首先创建一个配置文件/home/chenqionghe/test/prometheus/prometheus.yml
挂载之前需要改变文件权限为777,要不会引起修改宿主机上的文件内容不同步的问题
global:
scrape_interval: 15s # 默认抓取间隔, 15秒向目标抓取一次数据。
external_labels:
monitor: 'codelab-monitor'
# 这里表示抓取对象的配置
scrape_configs:
#这个配置是表示在这个配置内的时间序例,每一条都会自动添加上这个{job_name:"prometheus"}的标签 - job_name: 'prometheus'
scrape_interval: 5s # 重写了全局抓取间隔时间,由15秒重写成5秒
static_configs:
- targets: ['localhost:9090']
运行
docker rm -f prometheus
docker run --name=prometheus -d \
-p 9090:9090 \
-v /home/chenqionghe/promethues/server/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /home/chenqionghe/promethues/server/rules.yml:/etc/prometheus/rules.yml \
prom/prometheus:v2.7.2 \
--config.file=/etc/prometheus/prometheus.yml \
--web.enable-lifecycle
启动时加上--web.enable-lifecycle启用远程热加载配置文件
调用指令是curl -X POST http://localhost:9090/-/reload
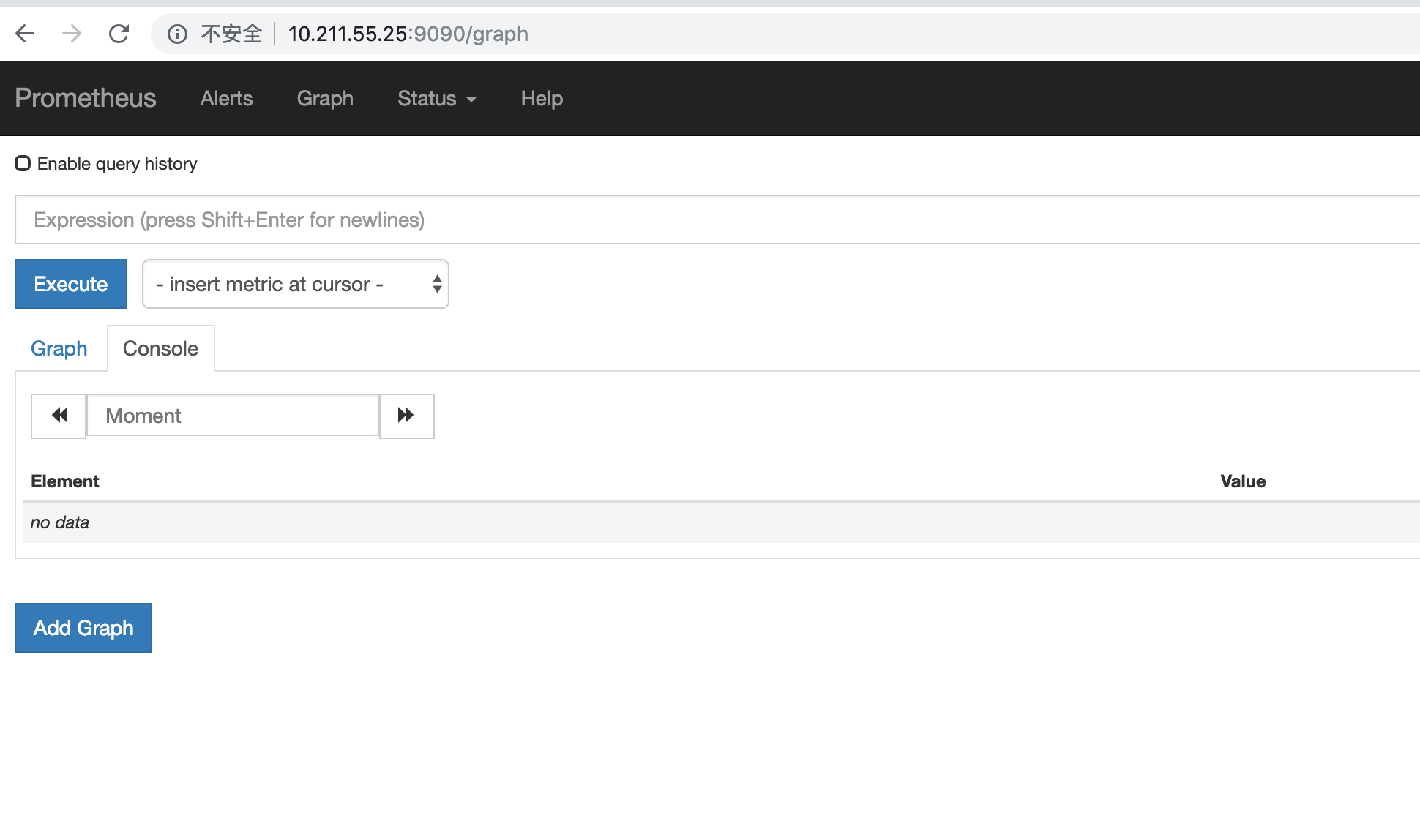
访问http://10.211.55.25:9090
我们会看到如下l界面
访问http://10.211.55.25:9090/metrics
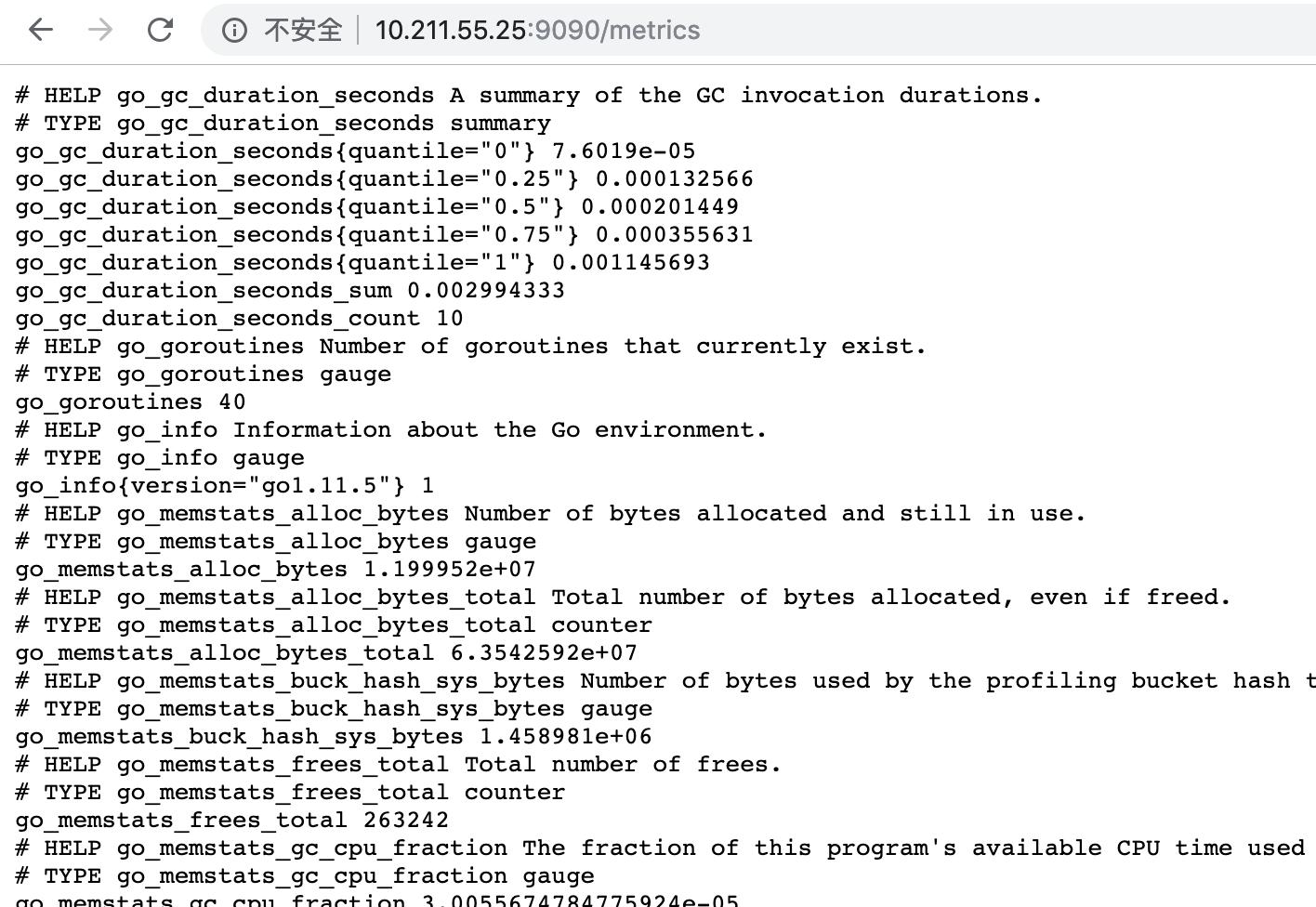
我们配置了9090端口,默认prometheus会抓取自己的/metrics接口
在Graph选项已经可以看到监控的数据

二.安装客户端提供metrics接口
1.通过golang客户端提供metrics
mkdir -p /home/chenqionghe/promethues/client/golang/src
cd !$
export GOPATH=/home/chenqionghe/promethues/client/golang/
#克隆项目
git clone https://github.com/prometheus/client_golang.git
#安装需要FQ的第三方包
mkdir -p $GOPATH/src/golang.org/x/
cd !$
git clone https://github.com/golang/net.git
git clone https://github.com/golang/sys.git
git clone https://github.com/golang/tools.git
#安装必要软件包
go get -u -v github.com/prometheus/client_golang/prometheus
#编译
cd $GOPATH/src/client_golang/examples/random
go build -o random main.go
运行3个示例metrics接口
./random -listen-address=:8080 &
./random -listen-address=:8081 &
./random -listen-address=:8082 &
2.通过node exporter提供metrics
docker run -d \
--name=node-exporter \
-p 9100:9100 \
prom/node-exporter
然后把这两些接口再次配置到prometheus.yml, 重新载入配置curl -X POST http://localhost:9090/-/reload
global:
scrape_interval: 15s # 默认抓取间隔, 15秒向目标抓取一次数据。
external_labels:
monitor: 'codelab-monitor'
rule_files:
#- 'prometheus.rules'
# 这里表示抓取对象的配置
scrape_configs:
#这个配置是表示在这个配置内的时间序例,每一条都会自动添加上这个{job_name:"prometheus"}的标签 - job_name: 'prometheus'
- job_name: 'prometheus'
scrape_interval: 5s # 重写了全局抓取间隔时间,由15秒重写成5秒
static_configs:
- targets: ['localhost:9090']
- targets: ['http://10.211.55.25:8080', 'http://10.211.55.25:8081','http://10.211.55.25:8082']
labels:
group: 'client-golang'
- targets: ['http://10.211.55.25:9100']
labels:
group: 'client-node-exporter'
可以看到接口都生效了
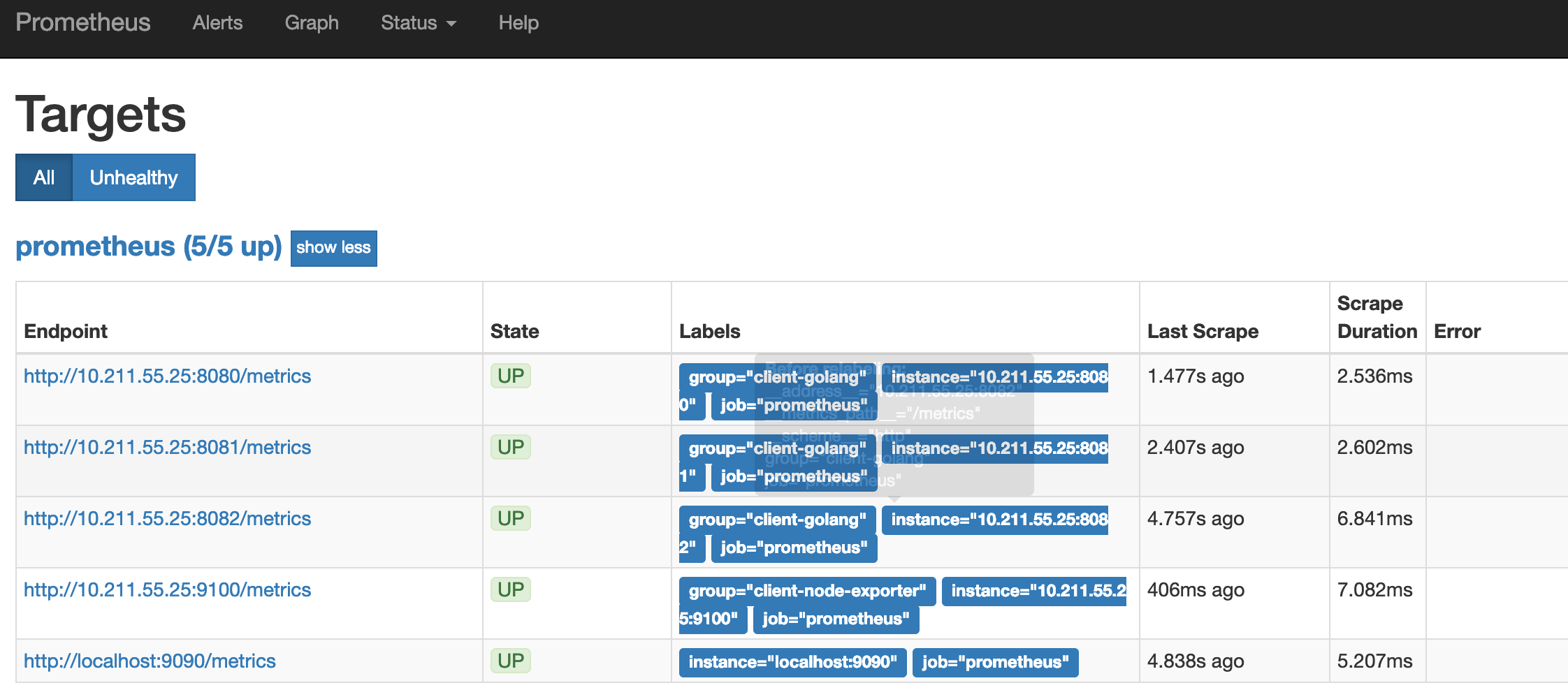
prometheus还提供了各种exporter工具,感兴趣小伙伴可以去研究一下
三.安装pushgateway
pushgateway是为了允许临时作业和批处理作业向普罗米修斯公开他们的指标。
由于这类作业的存在时间可能不够长, 无法抓取到, 因此它们可以将指标推送到推网关中。
Prometheus采集数据是用的pull也就是拉模型,这从我们刚才设置的5秒参数就能看出来。
但是有些数据并不适合采用这样的方式,对这样的数据可以使用Push Gateway服务。
它就相当于一个缓存,当数据采集完成之后,就上传到这里,由Prometheus稍后再pull过来。
我们来试一下,首先启动Push Gateway
mkdir -p /home/chenqionghe/promethues/pushgateway
cd !$
docker run -d -p 9091:9091 --name pushgateway prom/pushgateway
访问http://10.211.55.25:9091 可以看到pushgateway已经运行起来了
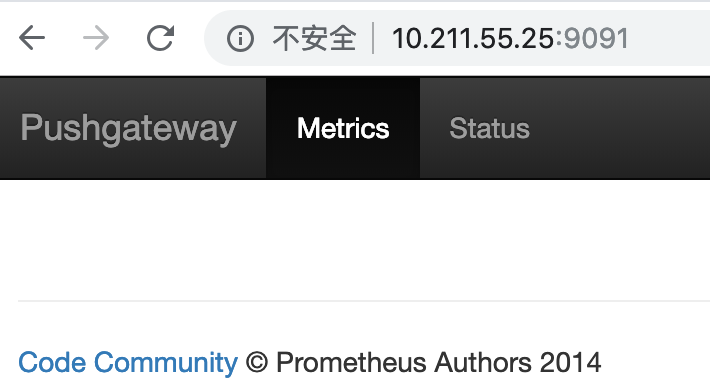
接下来我们就可以往pushgateway推送数据了,prometheus提供了多种语言的sdk,最简单的方式就是通过shell
- 推送一个指标
echo "cqh_metric 100" | curl --data-binary @- http://ubuntu-linux:9091/metrics/job/cqh
- 推送多个指标
cat <<EOF | curl --data-binary @- http://10.211.55.25:9091/metrics/job/cqh/instance/test
# 锻炼场所价格
muscle_metric{label="gym"} 8800
# 三大项数据 kg
bench_press 100
dead_lift 160
deep_squal 160
EOF
然后我们再将pushgateway配置到prometheus.yml里边,重载配置
看到已经可以搜索出刚刚推送的指标了
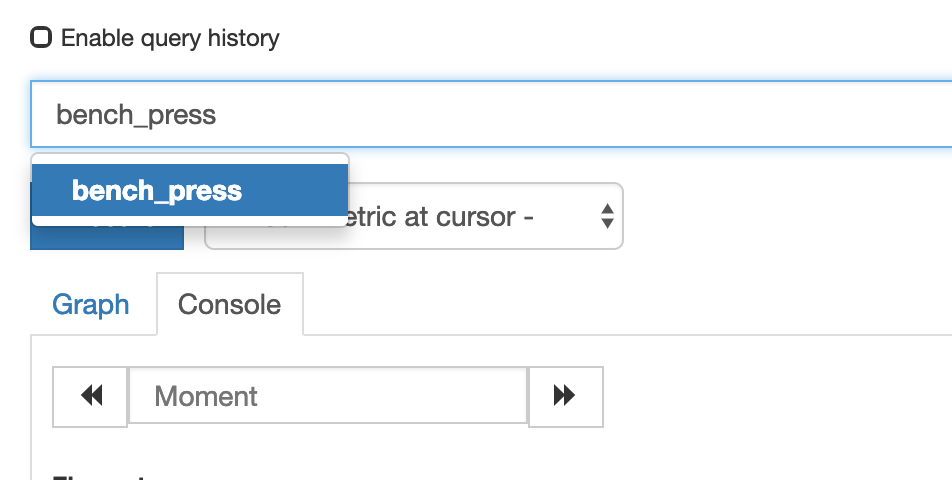
四.安装Grafana展示
Grafana是用于可视化大型测量数据的开源程序,它提供了强大和优雅的方式去创建、共享、浏览数据。
Dashboard中显示了你不同metric数据源中的数据。
Grafana最常用于因特网基础设施和应用分析,但在其他领域也有用到,比如:工业传感器、家庭自动化、过程控制等等。
Grafana支持热插拔控制面板和可扩展的数据源,目前已经支持Graphite、InfluxDB、OpenTSDB、Elasticsearch、Prometheus等。
我们使用docker安装
docker run -d -p 3000:3000 --name grafana grafana/grafana
默认登录账户和密码都是admin,进入后界面如下
我们添加一个数据源
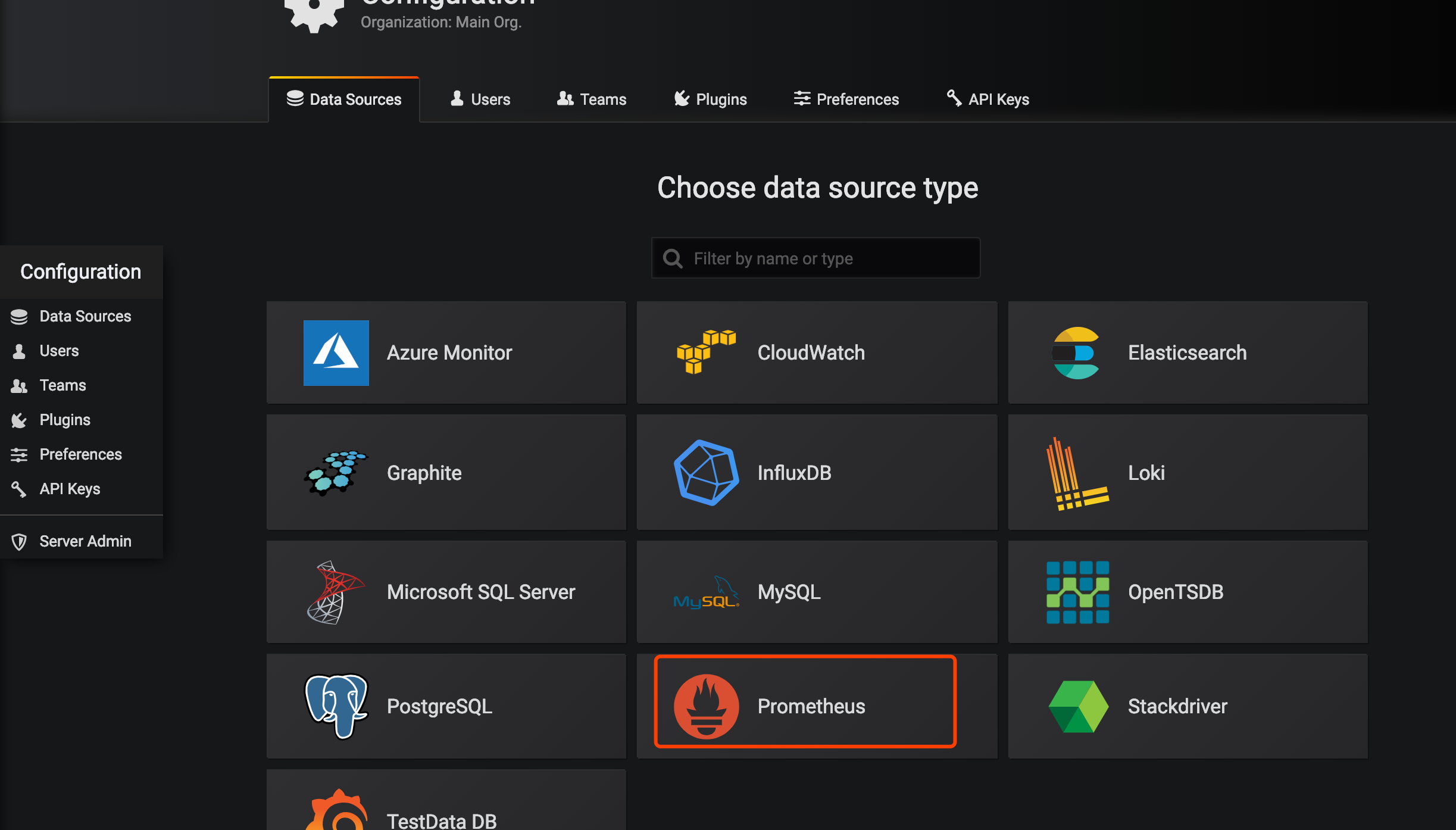
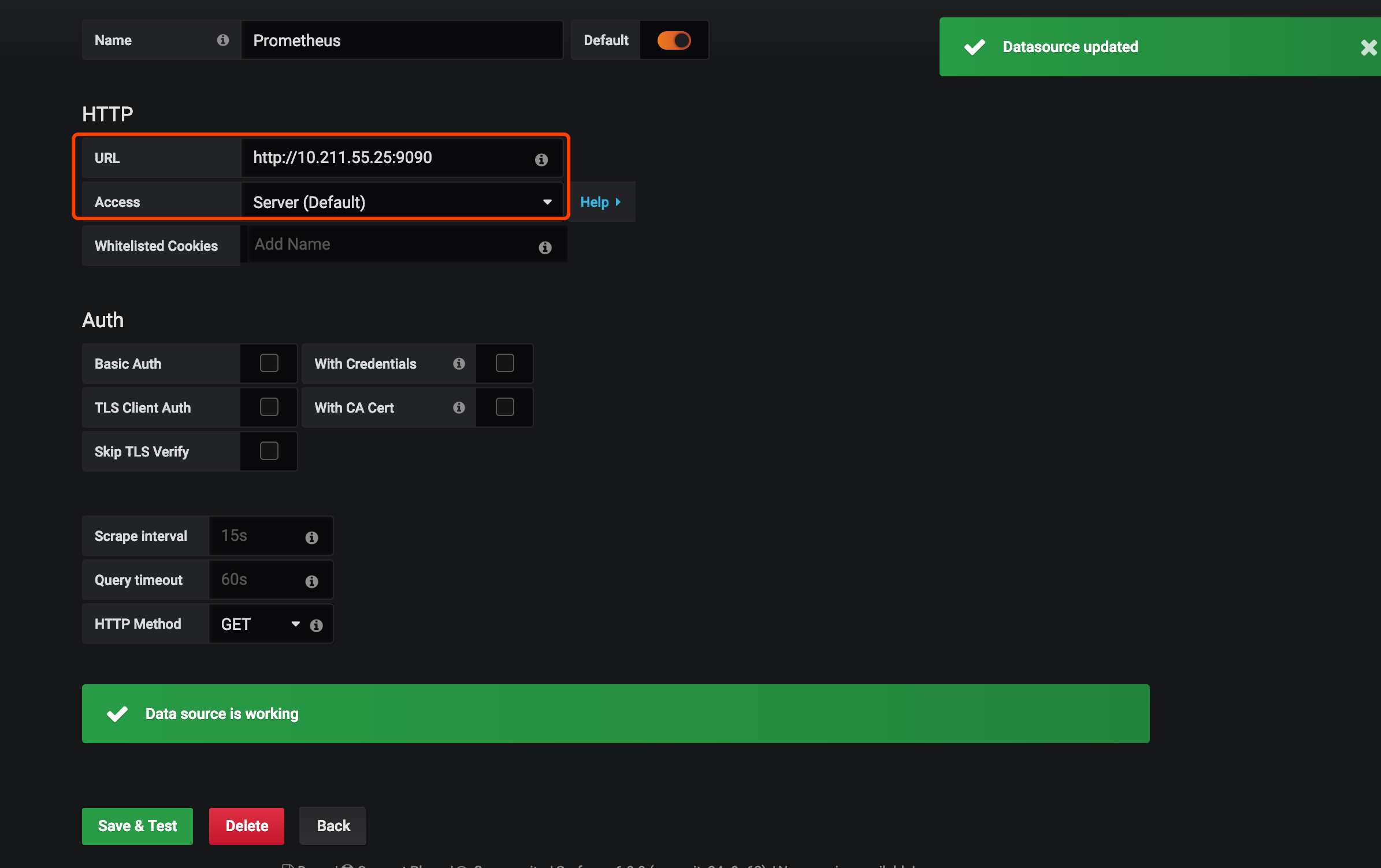
把Prometheus的地址填上
导入prometheus的模板
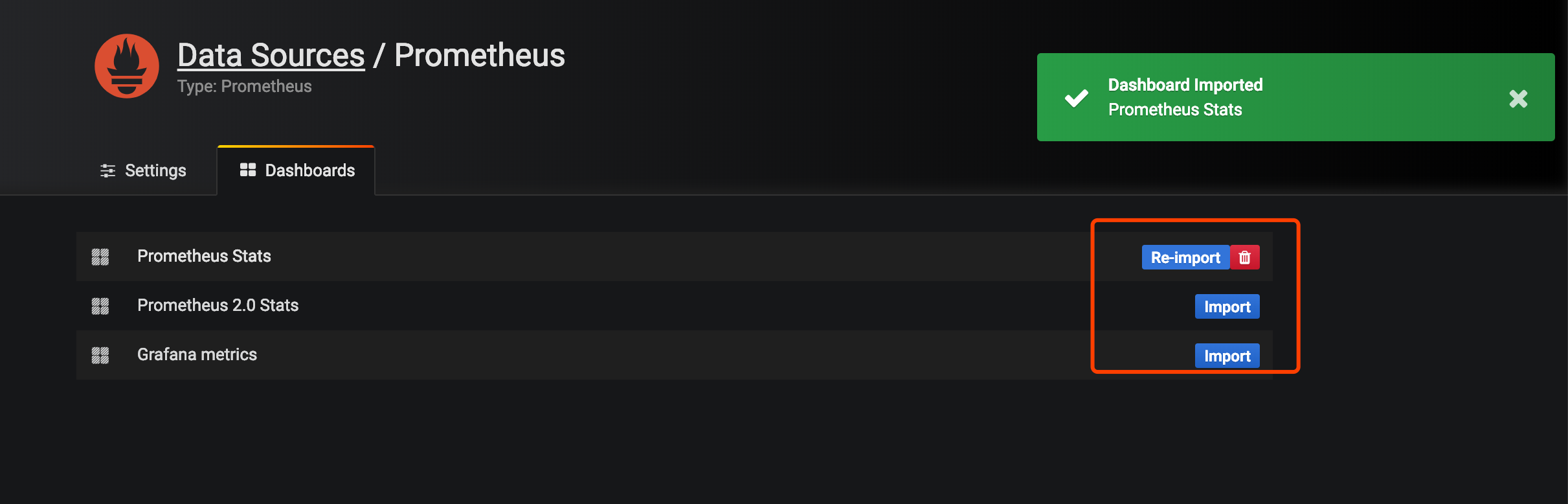
打开左上角选择已经导入的模板会看到已经有各种图
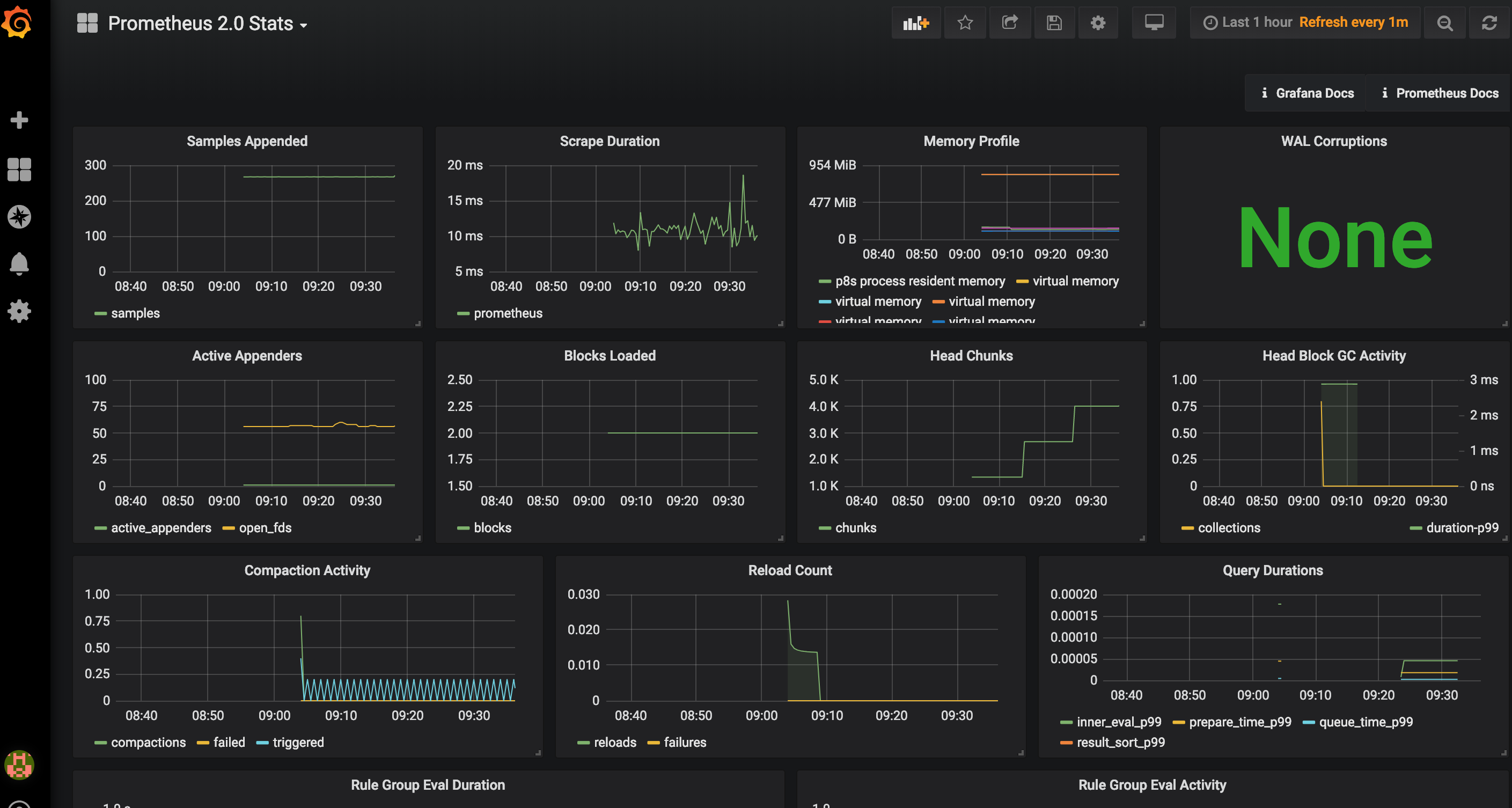
我们来添加一个自己的图表

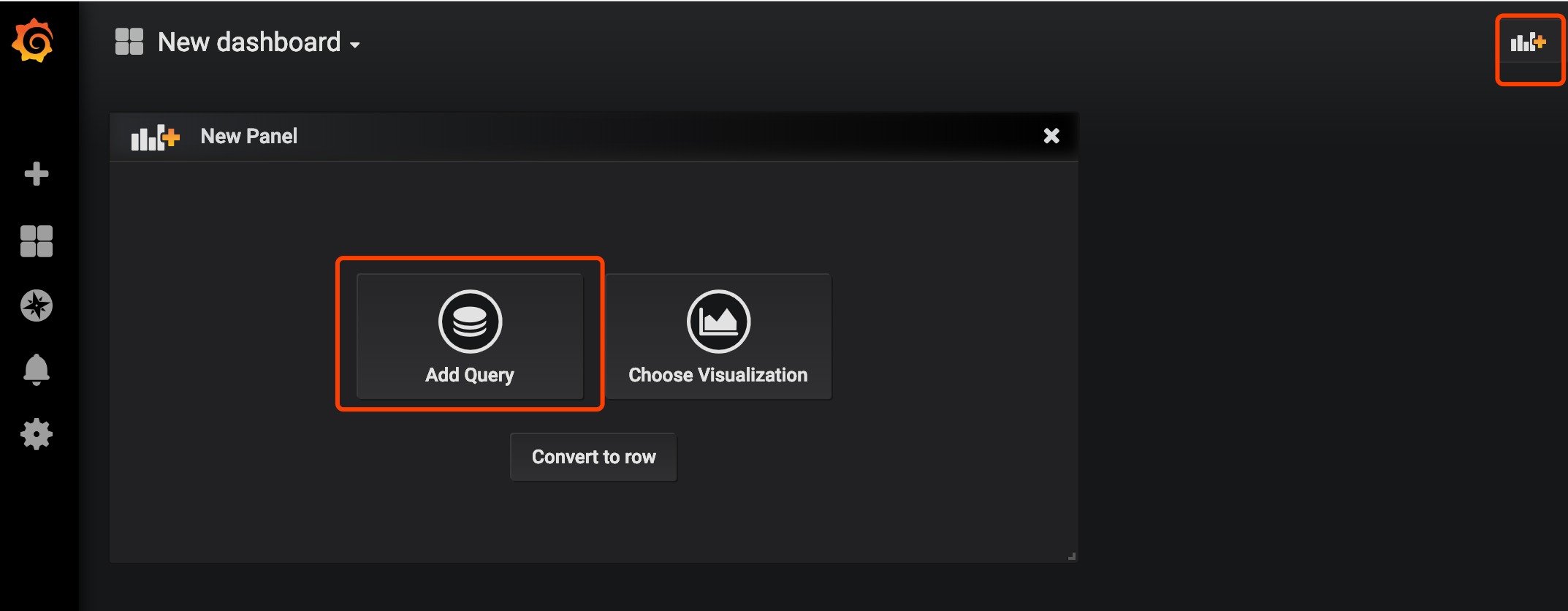

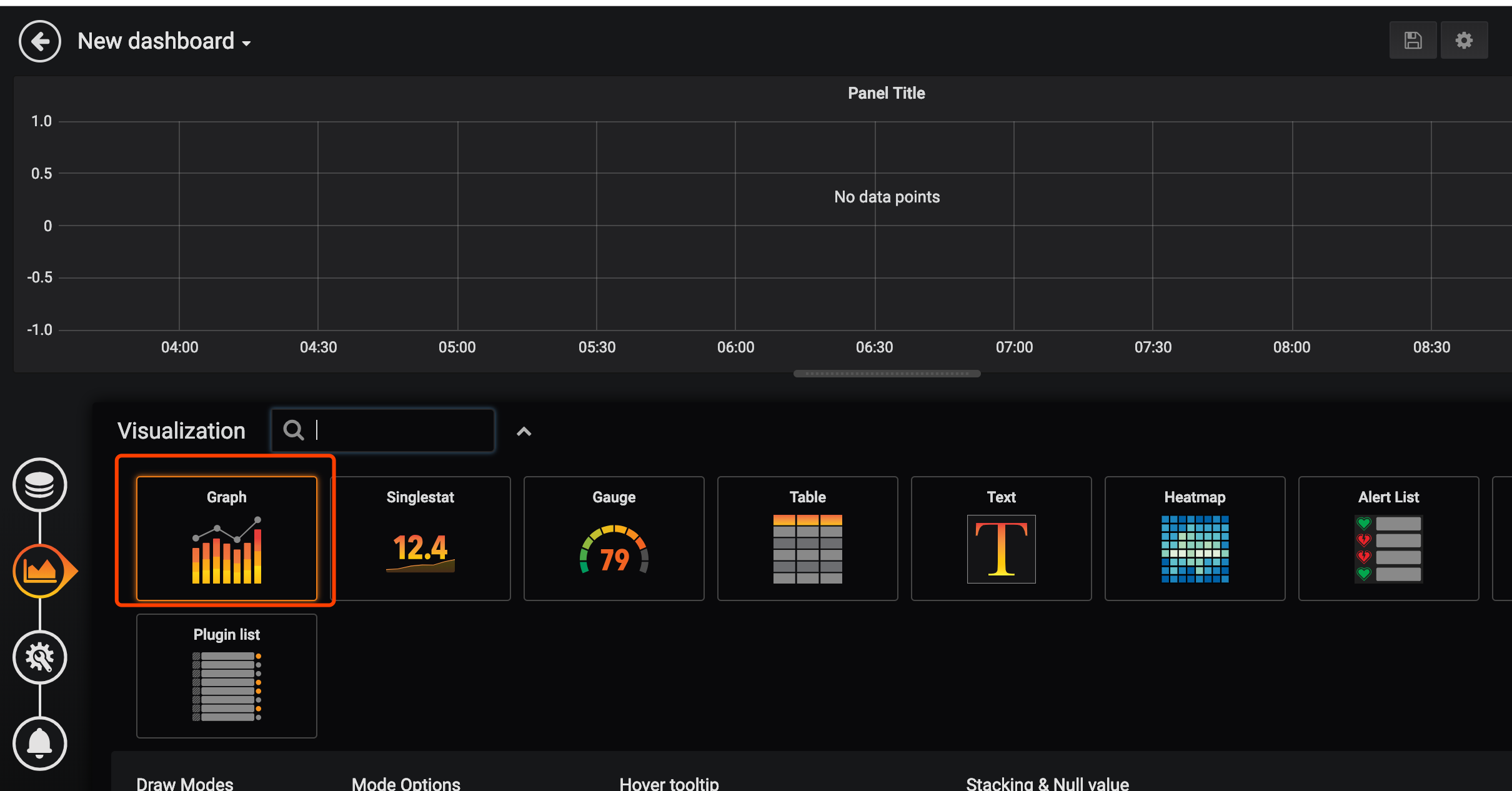
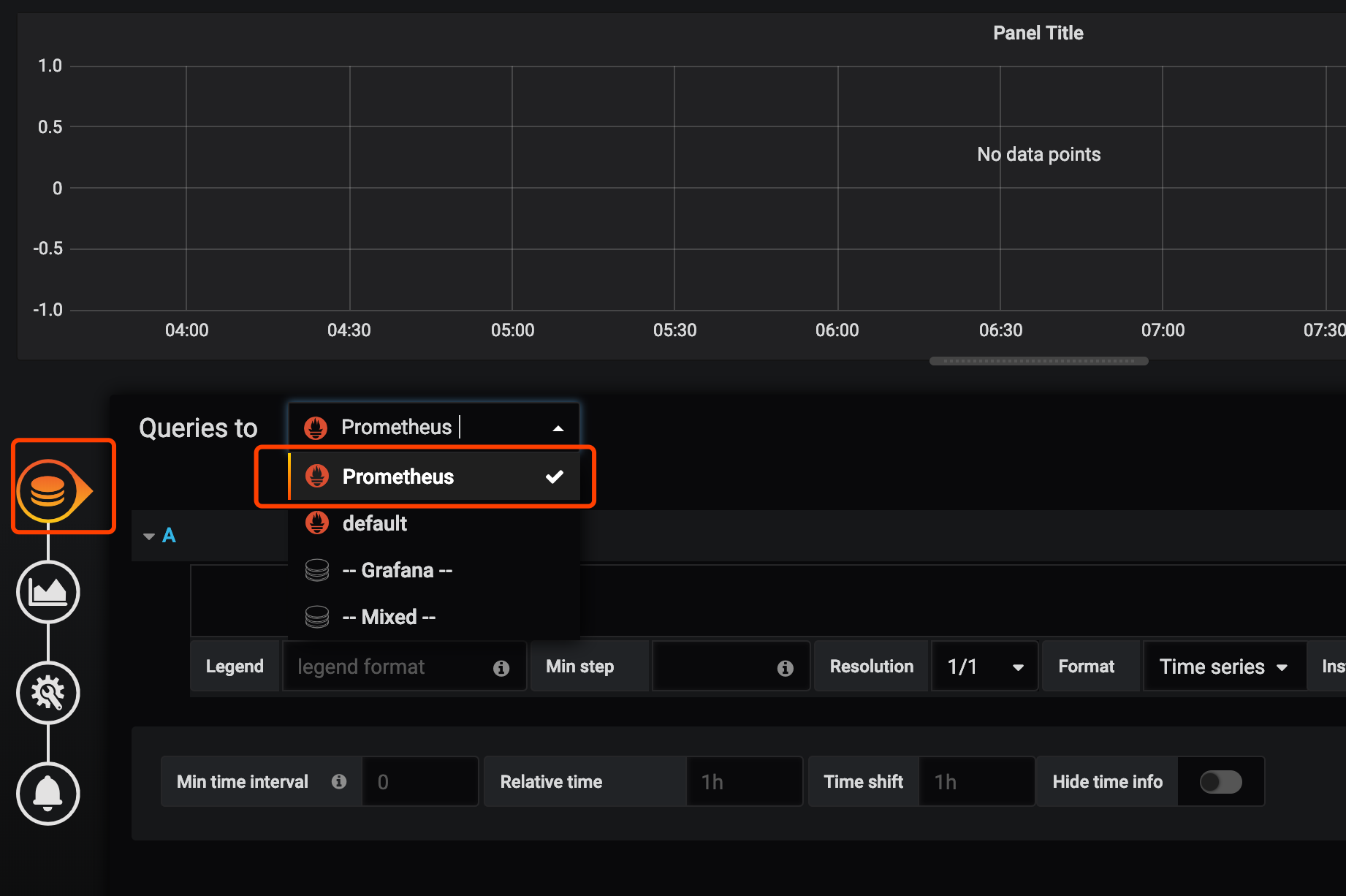
指定自己想看的指标和关键字,右上角保存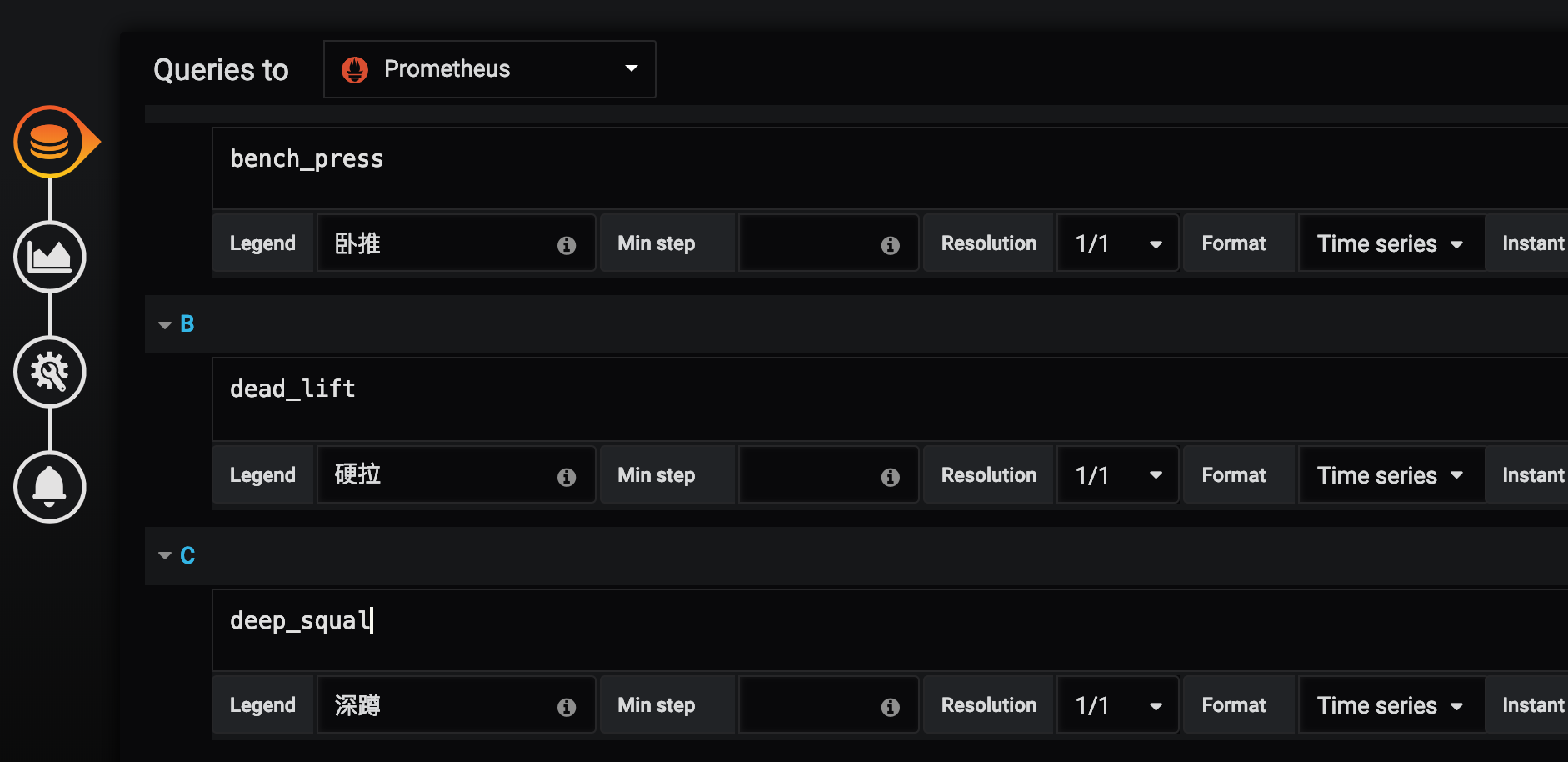
看到如下数据
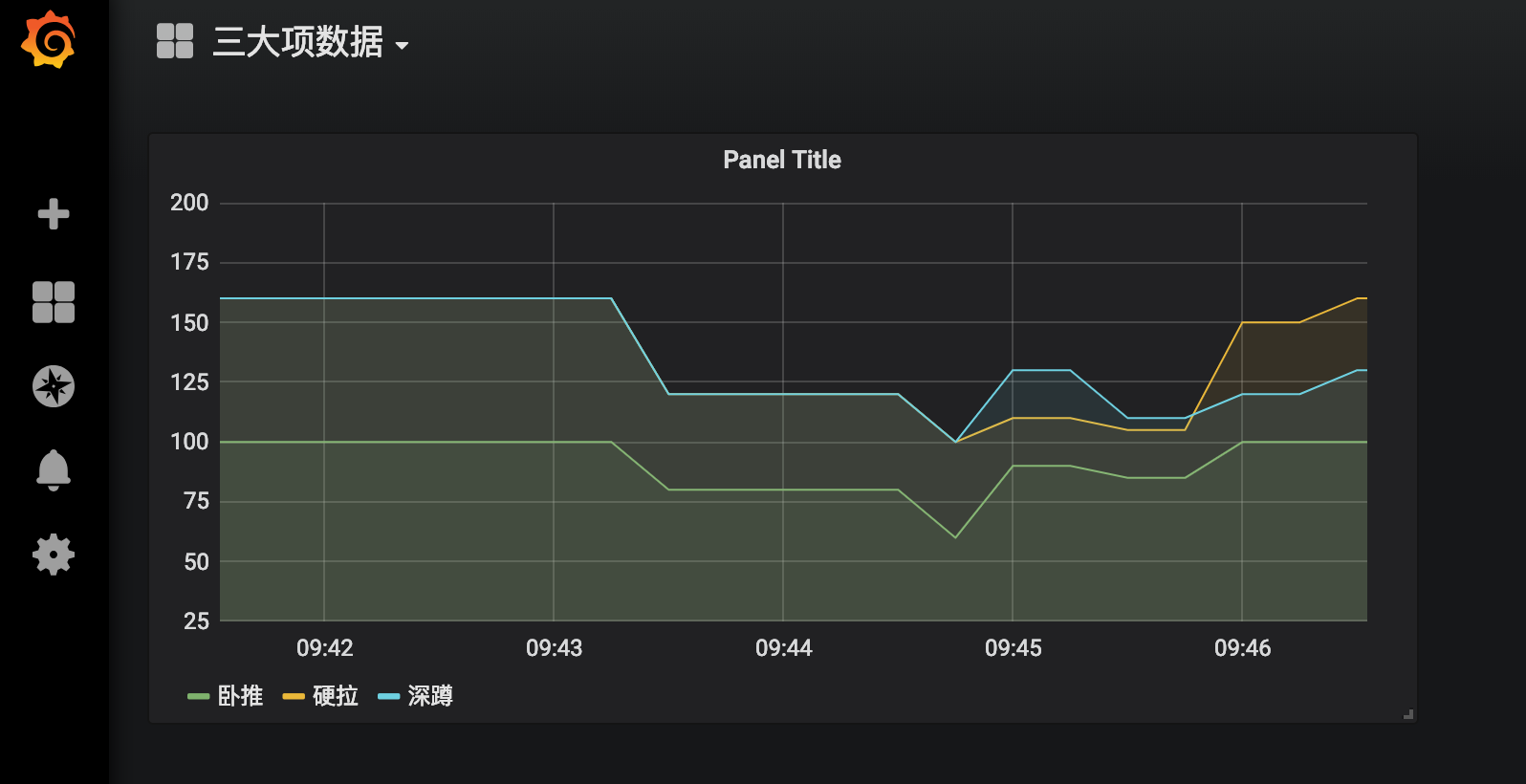
到这里我们就已经实现了数据的自动收集和展示,下面来说下prometheus如何自动报警
五.安装AlterManager
Pormetheus的警告由独立的两部分组成。
Prometheus服务中的警告规则发送警告到Alertmanager。
然后这个Alertmanager管理这些警告。包括silencing, inhibition, aggregation,以及通过一些方法发送通知,例如:email,PagerDuty和HipChat。
建立警告和通知的主要步骤:
- 创建和配置Alertmanager
- 启动Prometheus服务时,通过-alertmanager.url标志配置Alermanager地址,以便Prometheus服务能和Alertmanager建立连接。
创建和配置Alertmanager
mkdir -p /home/chenqionghe/promethues/alertmanager
cd !$
创建配置文件alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: ['cqh']
group_wait: 10s #组报警等待时间
group_interval: 10s #组报警间隔时间
repeat_interval: 1m #重复报警间隔时间
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://10.211.55.2:8888/open/test'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
这里配置成了web.hook的方式,当server通知alertmanager会自动调用webhook http://10.211.55.2:8888/open/test
下面运行altermanager
docker rm -f alertmanager
docker run -d -p 9093:9093 \
--name alertmanager \
-v /home/chenqionghe/promethues/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml \
prom/alertmanager
访问http://10.211.55.25:9093
接下来修改Server端配置报警规则和altermanager地址
修改规则/home/chenqionghe/promethues/server/rules.yml
groups:
- name: cqh
rules:
- alert: cqh测试
expr: dead_lift > 150
for: 1m
labels:
status: warning
annotations:
summary: "{{$labels.instance}}:硬拉超标!lightweight baby!!!"
description: "{{$labels.instance}}:硬拉超标!lightweight baby!!!"
这条规则的意思是,硬拉超过150公斤,持续一分钟,就报警通知
然后再修改prometheus添加altermanager配置
global:
scrape_interval: 15s # 默认抓取间隔, 15秒向目标抓取一次数据。
external_labels:
monitor: 'codelab-monitor'
rule_files:
- /etc/prometheus/rules.yml
# 这里表示抓取对象的配置
scrape_configs:
#这个配置是表示在这个配置内的时间序例,每一条都会自动添加上这个{job_name:"prometheus"}的标签 - job_name: 'prometheus'
- job_name: 'prometheus'
scrape_interval: 5s # 重写了全局抓取间隔时间,由15秒重写成5秒
static_configs:
- targets: ['localhost:9090']
- targets: ['10.211.55.25:8080', '10.211.55.25:8081','10.211.55.25:8082']
labels:
group: 'client-golang'
- targets: ['10.211.55.25:9100']
labels:
group: 'client-node-exporter'
- targets: ['10.211.55.25:9091']
labels:
group: 'pushgateway'
alerting:
alertmanagers:
- static_configs:
- targets: ["10.211.55.25:9093"]
重载prometheus配置,规则就已经生效
接下来我们观察grafana中数据的变化
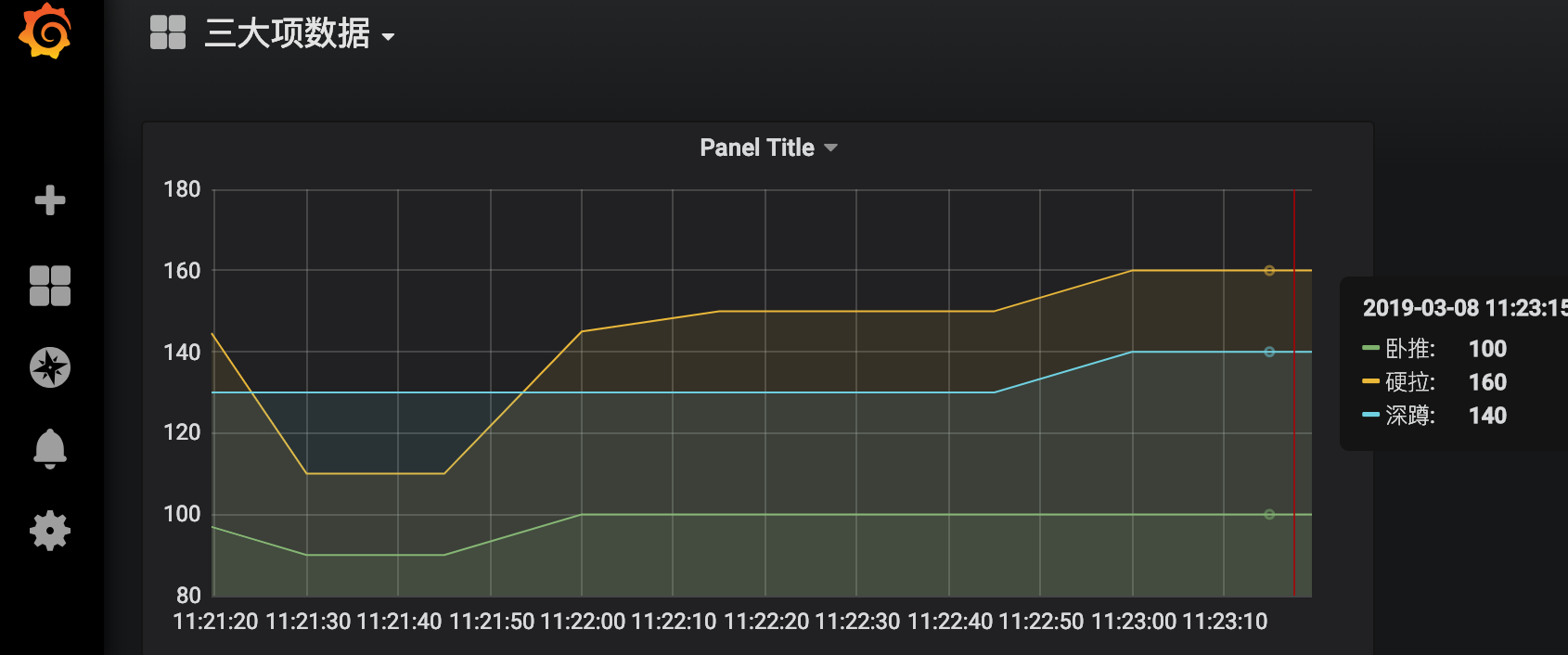
然后我们点击prometheus的Alert模块,会看到已经由绿->黄-红,触发了报警
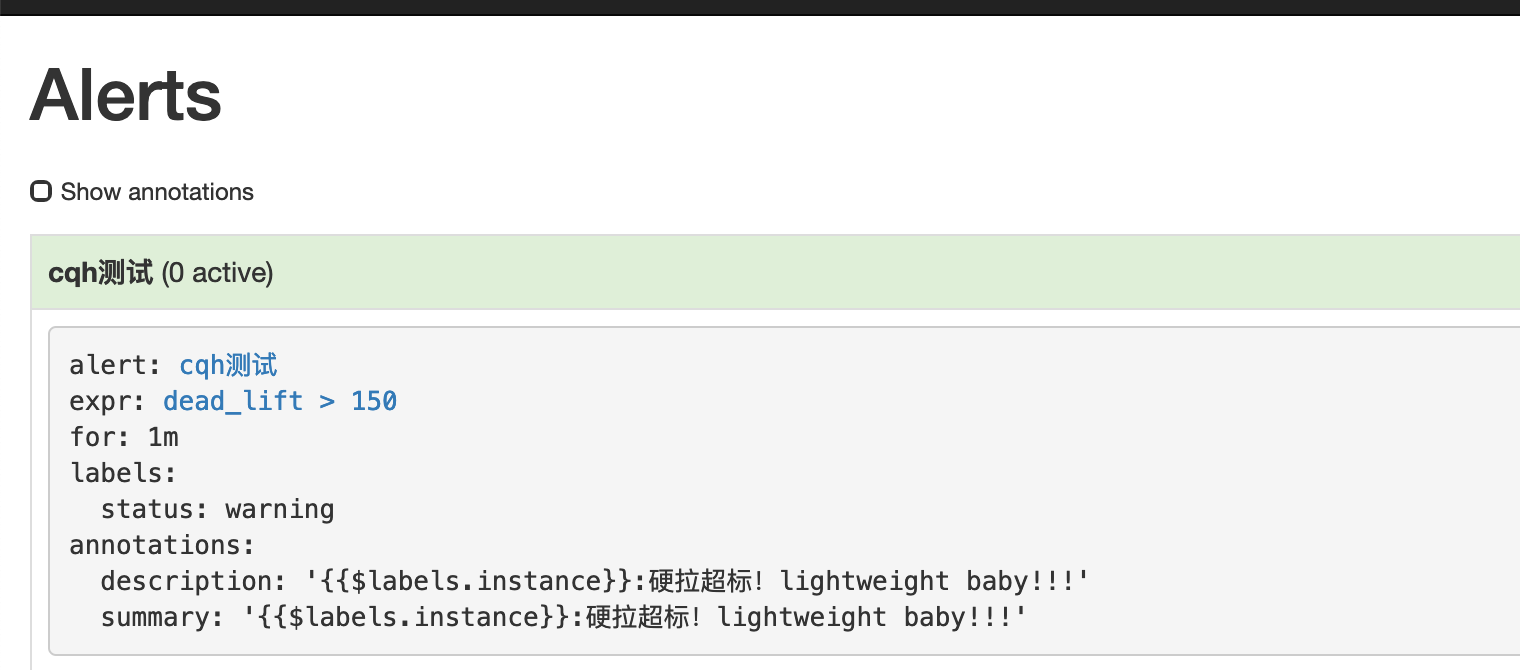
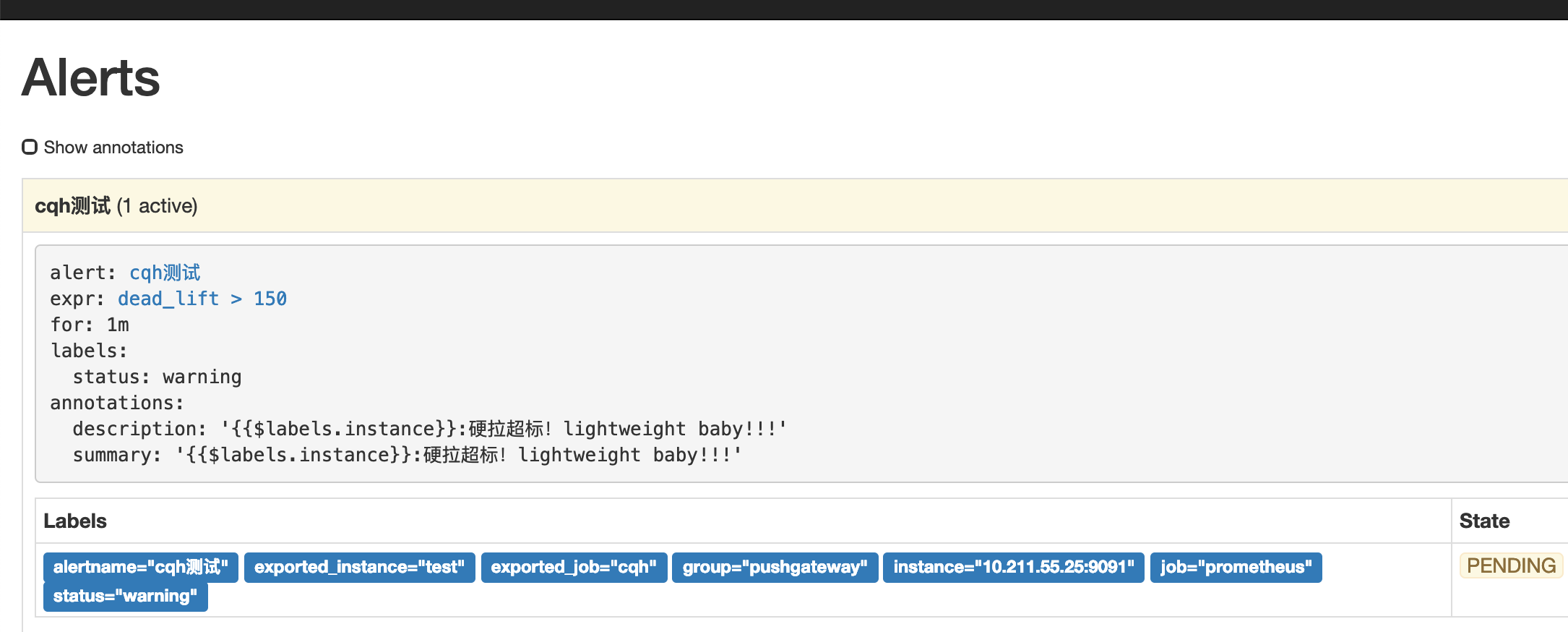


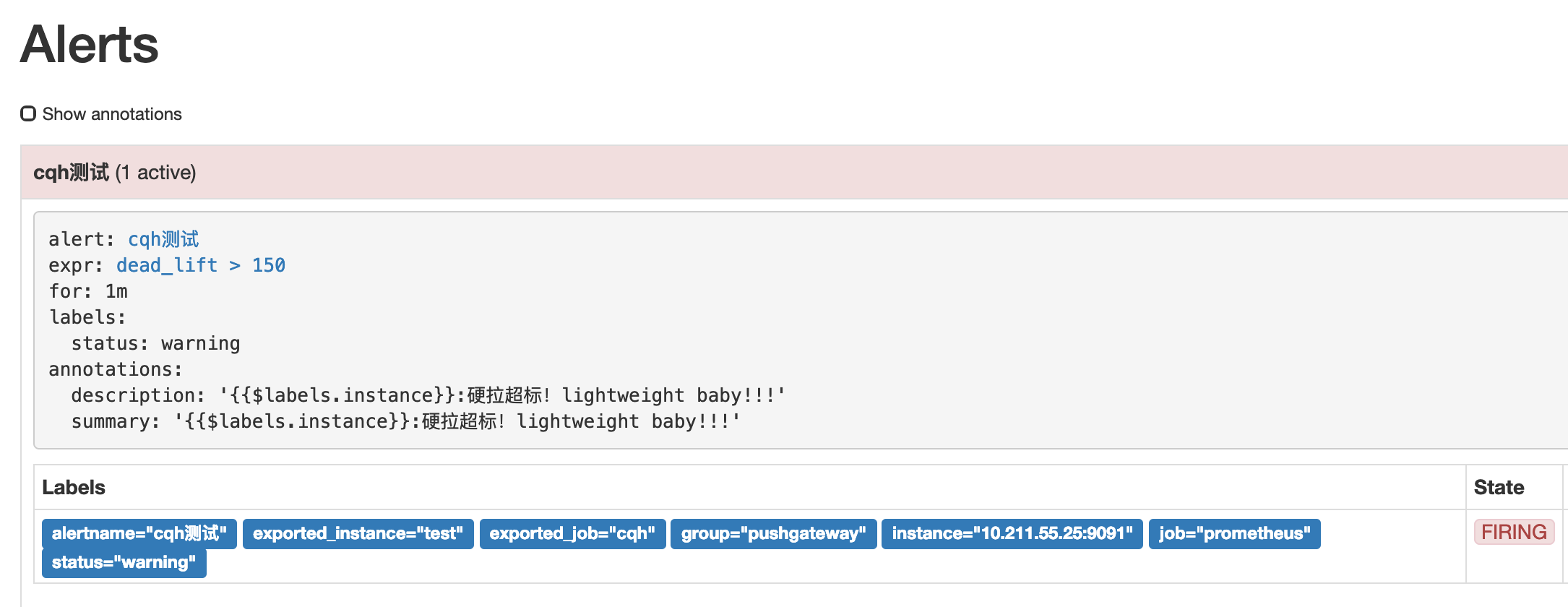
然后我们再来看看提供的webhook接口,这里的接口我是用的golang写的,接到数据后将body内容报警到钉钉
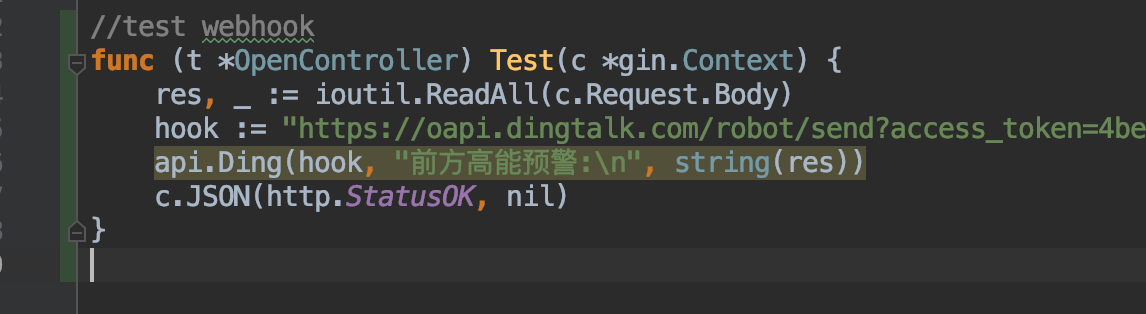
钉钉收到报警内容如下

到这里,从零开始搭建Prometheus实现自动监控报警就说介绍完了,一条龙服务,自动抓取接口+自动报警+优雅的图表展示,你还在等什么,赶紧high起来!
参考文档: